Parsing .ovr
shenyihong
Maintainer of ovr2shpHierarchical File Architecture(HFA) is Hexagon Geospatial's proprietary file format. It is the file format behind ERDAS Imagine .img files and ERDAS Imagine Annotation Layer .ovr files. It is not exactly the most "open" file standard out there, but luckily GDAL implements a raster driver for.img files, which offers an glimpse into the internals of HFA.
Now that we know that a open-sourced driver that can parse a file with the HFA format exists, we can use that as our starting point.
My Goal: Convert Erdas Imagine Annotation Layer(.ovr) to ShapeFile(.shp)
The problem, however, is that GDAL is bulky and I have limited experience dealing with big c++ projects. Since we would only need specific files to parse HFA compliant files, I went digging for something more lightweight. I managed to find a web archive page that contained a early version of a .img to .tif converter. You can find the page here.
This page also turns out to be the holy grail as it also referenced a detailed documentation of .img file format and the internals of HFA
img2tif#
The source code included drivers for HFA and GeoTIFF, but there is just one caveat: The HFA driver included is not a general implementation but rather one that is specifically made for .img. It is the same case for the HFA driver in GDAL.
Fortunately, it has all the low-level implementations included to parse raw bytes into a generic higher level HFA data classes.
What's left for me is to fill in the gaps by implementing high level representations of data types found in a .ovr HFA structure. With a few changes, I was able to integrate this driver to successfully parse a .ovr file.
Hierarchical File Architecture (HFA)#
Hidden within the detailed documentation lies the secrets to HFA.
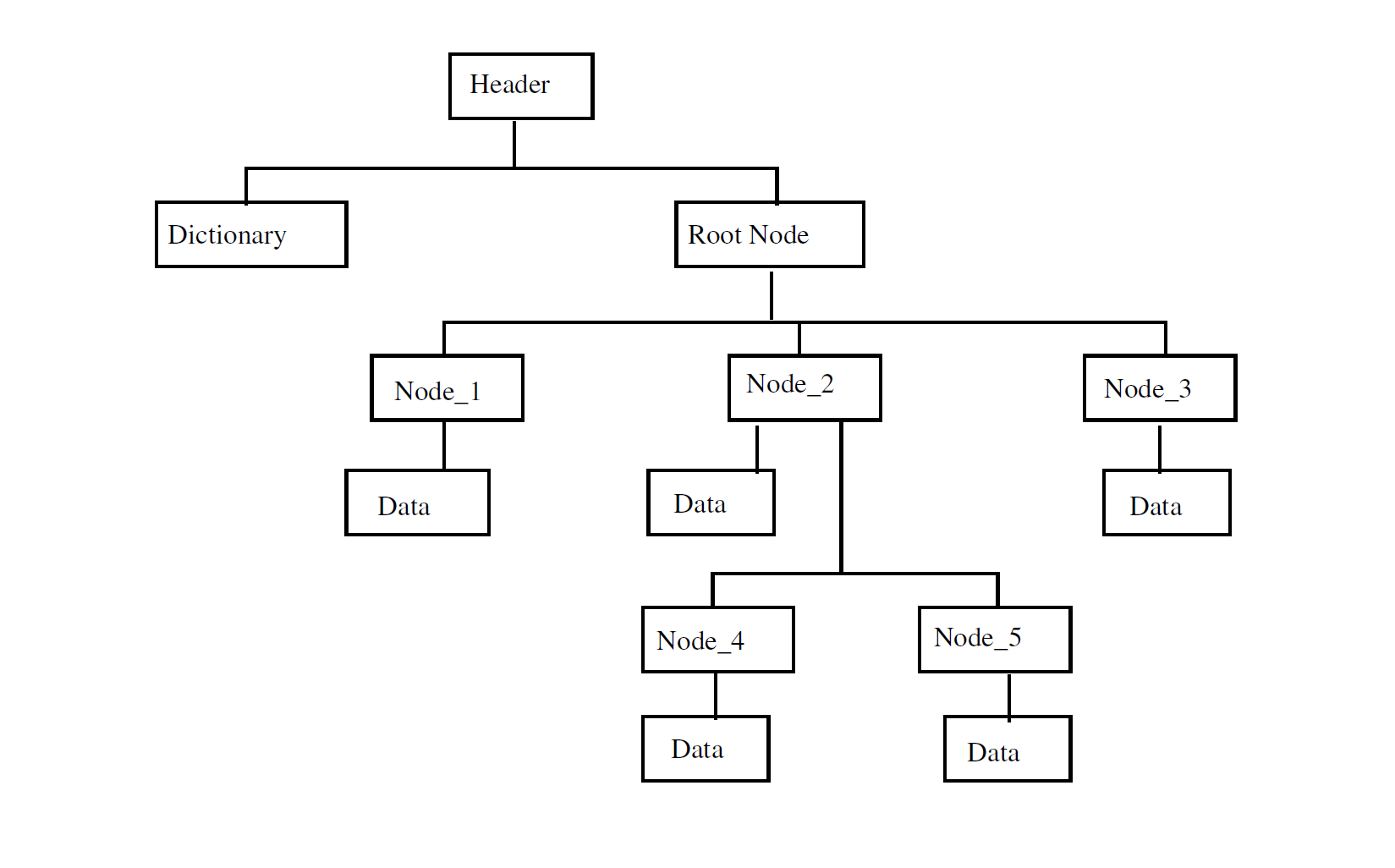
The hierarchical file architecture maintains an object−oriented representation of data in an ERDAS IMAGINE disk file through use of a tree structure. Each object is called an entry and occupies one node in the tree. Each object has a name and a type. The type refers to a description of the data contained by that object. Additionally each object may contain a pointer to a subtree of more nodes.
Header Tag#
- dtype:
Ehfa_HeaderTag - size:
20b- First
16bcontains the unique signature of a ERDAS IMAGE HFA File: EHFA_HEADER_TAG - Remaining
4bcontains the file pointer to the header record
- First
The header tag does not correspond to the header node shown in the diagram above! This is just a tag that contains a reference to the header node
The value of a file pointer is simply the number of bytes from the start of the file
Header Record#
- dtype:
Ehfa_File - The header record contains file pointers to the Root node of the HFA Tree and the MIF (Machine Independent Format) Dictionary.
- MIF Dictionary stores all the type information for each kind of node in the HFA Tree.
MIF Dictionary#
- dtype:
char* - The MIF Dictionary contains different type information for different nodes in the HFA Tree. Hence, the dictionary must be read and decoded before any of the other objects in the file can be decoded
Type information is encoded like such:
num_element: Number ofdtype_charelement- Example: To encode the Header Tag in the
Ehfa_HeaderTagdata type, each of the first16bhas achardtype occupying1bof space. To encode the entire tag 16charis needed, hence{16:clabel}
- Example: To encode the Header Tag in the
dtype_char: MIF data type identifier
attr_name: Name of attribute under typedtype_identifier: data type of node
Root Node#
dtype:
Ehfa_EntryThe root node is the entry point into the main HFA tree structure. By traversing down the tree from the root, data nodes (where the "gold" is at) can extracted
A
Ehfa_Entrydtype contains file pointers to the next node and child node. We use these pointers to traverse down the HFA Tree.- Next Node: The node "right" of the current node on the same level
- Child Node: "Left-Most" child node
Ehfa_Entry#
Ehfa_Entry is data type representing the nodes of the HFA tree structure. A single Ehfa_Entry contains "tree" level attributes (file ptr to child node, name of node etc.) and a file pointer reference to the data block.
To be put it simply, there are 2 different sections to a Ehfa_Entry
To dive deeper into the 2 sections, let's look at the type definition of Ehfa_Entry found in the MIF Dictionary
{1:Lnext,1:Lprev,1:Lparent,1:Lchild,1:Ldata,1:ldataSize,64:cname,32:ctype,1:tmodTime,}Ehfa_Entry,
Base section
- Tree level attributes/metadata (attributes in the type definition above are all tree level attributes)
Tree level attributes can be interpreted as meta attributes that allow traversal of the tree structure without ever requiring to touch the data residing in it
- Tree level attributes/metadata (attributes in the type definition above are all tree level attributes)
Data section
- Data within the node (annotation name, coordinates etc.)
- The data block can be accessed using the file pointer value found in the
dataattribute{1:Ldata}contains the file pointer to the data node - The data that resides in the node has a corresponding data type that can be found in the MIF Dictionary. The data type is identifiable by the
typeattribute seen above.{32:ctype}contains the data type identifier
In order to extract the data we are interested in, we will seek the specified file position in the data attribute and parse the bytes into the higher level data structure specified in type attr.
The following are examples of data type identifiers that can be found in a Ehfa_Entry:
Rectangle2: Contains geometric definitions of ERDAS Rectangle AnnotationsEprj_MapInfo: Contains image map coordinatesEprj_ProParameters: Contains projection parametersEprj_Datum: Contains datum information